Připravuji školení na jazyk SQL (v MS SQL) pro začínající správce Helios, tak to rovnou sepisuji.
Chci minimum teorie, maximum příkladů. Tedy více selectu a méně deletu.
Příprava:
- Nainstalované management studio
- Přístup do databází na nějakém SQL serveru. Ideálně databáze Helios. Je lepší udělat testovacího uživatele.
- Nějaký folder, kde se budou ukládat scripty.
- Přístup do Helios (případně zase testovacího uživatele v Helios)
- Nahrávání obrazovky zprovoznit
SQL Server Management Studio (SSMS):
- Je to nástroj pro správu SQL serverů a jeho komponent. Místo kde se píšou selecty.
- Stažení, Instalace (next, next, next) , Spuštění
- Připojení se (služba/server/authentification/user). Server může být IP adresa nebo localhost (tečka).
- Seznam databází a co je vevnitř (tabulky, procedury…)
- Na jakou databázi jsem připojený a jak to změním (příkaz USE)
- Nalezení objektu (prostě píšu a on doskakuje).
- Scriptování objektů
- Na tabulce vyscriptovat příkaz „Select top 1000 rows“
- Příkaz USE DATABASE a základní logika dotazovacího jazyka.
- Něco pošlu (execute), vrátí se mi výsledek
- F5 pro spuštění
- Spuštění jen zamodřeného
- Více příkazů za sebou (go, středníky)
- Komentování
- — co je v řádku za tímto neplatí
- /* co je uvnitř neplatí */. Nedá se vnořovat.
- Více oken (už nespadne při změně pořadí 🙂
- Bacha na to co děláte, tady není prostor pro chybu! (delete nad databází/tabulkou).
Tabulky
- Tabulky jsou základ
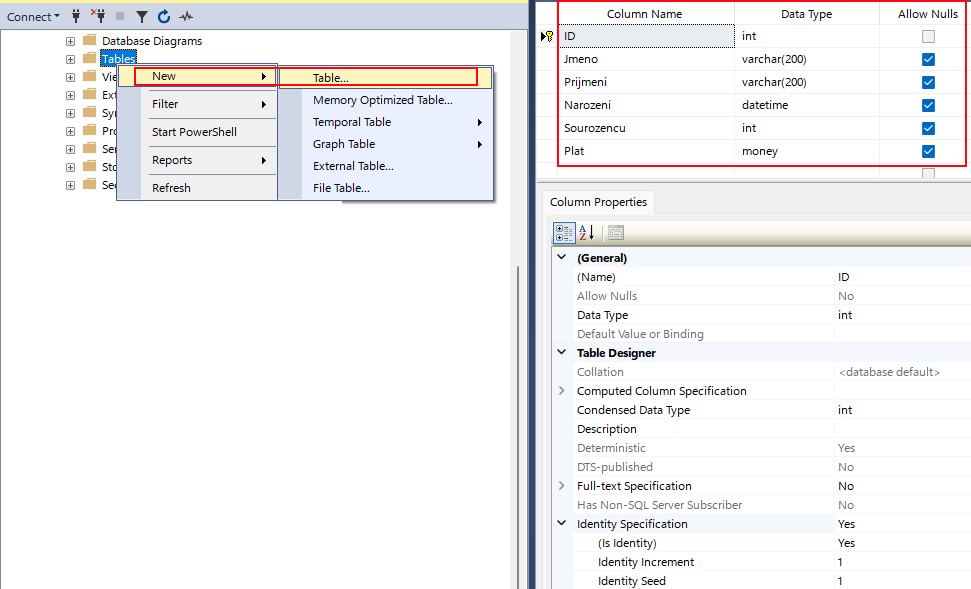
- Vytvoření tabulky v management studiu
- Primární klíč, co to je.
- Celý sloupec má nějaký datový typ. Tím je určeno, co v něm může být uloženo za hodnoty
- Číslo – INT, NUMERIC, MONEY
- Datum – DATE DATETIME
- Řetezec – v apostrofech, různá délka, CHAR, VARCH, NVARCHAR
- Atd.
- Specifická je hodnota null
- Najít vytvořenou tabulku, vyscriptovat
- Vložit nějaké hodnoty přes SSMS
Příkaz SELECT
- Naprosto nejdůležitější příkaz. 80% mé práce je příkaz SELECT .
- Select je z tabulek (většinou) a vrací tabulku (většinou).
- Zobrazte si tabulku lcs.organizace (script select). Kolik je to záznamů?
- V IS Helios v přehledu STR+SHIF+S se zobrazí aktuální select přehledu.
- Pro zformátování selectu používám poorsql.com.
USE MojeDatabaze
GO
SELECT
o.cislo_subjektu as CS
,o.reference_subjektu as Cislo
,o.nazev_subjektu as Nazev
,o.ico
,o.ulice
,o.misto
,o.zeme
,o.poznamka
-- SELECT TOP 100 *
-- SELECT count(*)
FROM lcs.organizace o
WHERE 1=1
AND o.nazev_subjektu like '%test%'
AND o.ico is not null
ORDER BY 2 ASC ,cislo_subjektu DESCNejprve se dívám (píšu) na FROM.
- Za FROM je první tabulka (view).
- Následuje více tabulek spojených pomocí JOINy (viz víže).
- Tečková konvence Server.Databaze.Vlastnik.Tabulka AS AliasTabulky.
AS je nepovinné (u tabulek obvykle nepíšu) - Hranaté závorky, kdy jsou nutné (aneb tabulka s názvem [SELECT], [TABULČIČKA]). Diakritika se nepoužívá.
Pak se dívám na sloupce (za SELECT) :
- Na začátku je SELECT, nechávám na samostatném řádku (lépe se formátují sloupce, dá se pak přidat TOP)
- Následují sloupce (musí být z některé tabulky, které je za FROM):
- Za sebou (když je sloupců málo)
- Pod sebou (když je sloupců hodně). Čárku vždy na začátek (jinak budete čárky pořád hledat)
- Syntaxe pro sloupec je:
- AliasTabulky.SloupecAS AliasSloupce (doporučuji!)
- Sloupec (ne úplně doporučuji – nefunguje doplňování po tečce)
- Tabulka.Sloupec AliasSloupce (nedoporučuji – moc psaní, málo přehledné. To AS se zde hodí)
- Výraz AS AliasSloupce (zde doporučuji alias použít)
- Hvězdička (*) znamená všechny sloupce. Dá se kombinovat s názvů sloupců.
Výrazy
- Ne vždy potřebuji celý sloupec, často potřebuji nějak ho upravit
- Můžu použít operátory jako násobení, dělení, slučování řetězců (v MSSQL + )
- Můžu použít funkce (LEFT, GETDATE(), TRIM, SUBSTRING). Dokonce i funkce Heliosu
- Bacha na agregační funkce vysvětluji níže.
- Bacha na hodnotu null. Není to ani tak hodnota jako spíš vlastnost.
Omezení vrácených řádků podmínkou WHERE .
- WHERE dělá vždy to samé – zmenšuje počet záznamů. Vždy si kontroluji počet vrácených záznamů.
- Standardní podmínky vypadají:
AND Sloupec1 operátor podmínka1
AND Sloupec2 operátor podmínka2 - Operátory jsou například
- =, >,<, <=,>=
- LIKE ‚%textový řetězec%‘ – procento nahrazuje libovolné znaky, podtržítko jeden.
- IS, IS NOT – používá se pro null
- IN (hodnota1,hodnota2)
- BETWEEN hodnota1 AND hodnota2 – nepoužívám, místo toho dávám dvě podmínky > a <.
- Za WHERE vždy píšu 1=1. Můžu pak zakomentovat i tu první podmínku a mám podmínky vizuálně pod sebou.
- Kromě podmínky AND se může použít i OR. Platí boolean logika. Zjednodušeně – OR, vždy dávejte do závorek! Typicky takto:
AND Sloupec1 = podmínka1
AND Sloupec2 = podmínka2
AND (Sloupec3 = podmínka3 OR Sloupec3 = podmínka4)
Setřídění výsledku pomocí ORDER BY.
- Protože výsledek selectu je tabulka, můžu chtít aby byla setříděná.
- Setřídění je podle sloupců. Může jich být více a nemusí být ve výsledku.
- ORDER BY se píše za WHERE a je to v podstatě seznam sloupců oddělených čárkami.
- Za sloupcem se jak chci setřídit:
- ASC = sestupně (nejstarší nahoře) a je výchozí (nemusí se psát)
- DESC je sestupně (nejnovější nahoře)
- ORDER BY Sloupec1 ASC, Sloupec2 DESC
- Order by je vždy úplně na konci (je to logické, protože se týká až toho výsledku)
Omezení počtu vrácených řádků TOP.
- Je to podobné jako WHERE.
- Ale provede se na konci a prostě ořízne co se vrátí na klienta
- Hodně se používá s ORDER BY. Třeba když chcete řádek s nějakou maximální hodnou. Například poslední změněné záznamy Helios:
SELECT TOP 10 *
FROM lcs.subjekty s
ORDER BY s.last_update DESCDISTINCT
- Ve výsledné tabulce zobrazí stejné řádky jen jednou
- Neboli vyhází duplicitní řádky
- Je to takové zjednodušení, univerzálnější je GROUP BY, na které se dá vždy převést.
- Používám obvykle na jeden sloupec, když chci vědět jaké různé hodnoty v něm jsou
SELECT distinct exchange_address
from lcs.OrganizaceVíce tabulek aneb JOINY aneb sranda začíná
- V tabulce bývá většinou tzv. Primární klíč. Potřebuji nějak adresovat konkrétní záznam, musím ho najít.
Obvykle se používá vzestupné číslování (cislo_subjektu). - Helios je specifický, primární klíč chce mít přes všechny (subjektové) tabulky. Proto má velkou tabulku lcs.subjekty kde je cislo_subjektu zjednoznačněné. A když už tam je cislo_subjektu duplicitně s tabulkou, tak se tam přidala a reference_subjektu (číslo záznamu) a nazev_subjektu (název záznamu).
Říká se tomu posun do meta a má to nějaké výhody (nemusím do tolika tabulek) a spoustu nevýhod (složitější, častější zamykání, pomalejší, hůře se píšou selecty, nesmí se rozjet, hůře se nad tím programuje atd. atd.). - Vazby (=reference, vztahy, … ) mezi tabulkami se dělají tak, že mám ve svojí tabulce jen primární klíč jiné tabulky. Tím mám vazbu na konkrétní řádek.
- Tato vazba se označuje 1:N. Existují i vazby 1:1 (velmi zřídka) a vazba M:N (ta se mezitabulkou převádí na 1:N N:1.)
- Musím zajistit, že v mojí tabulce je existující cislo_subjektu (ID) druhé tabulky. Tomu se říká referenční integrita. Používají se cizí klíče (ale nikoli v Heliosu)
- Vycházím z jedné tabulky (obvykle z té největší) a dotahuji (joinuji přivazuji) záznamy dalších tabulek. Můžu to řetězit jak chci.
- Základní syntaxe je JOIN table ON Spojovací podmínka1 AND Spojovací podmínka1.
SELECT a.*
FROM tableA a
JOIN tableB b ON b.Sloupec1 = a.Sloupec1
LEFT OUTER JOIN tableC c ON c.Sloupec1 = a.Sloupec2 - Můžu použít stejnou tabulku i vícekrát (ale musí mít jiný alias)
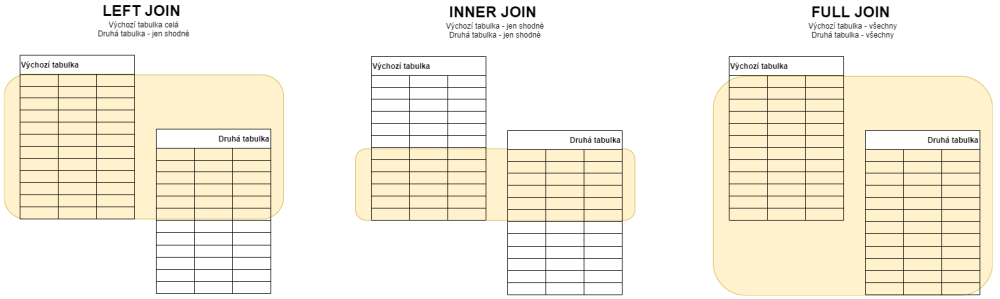
- Druhy joinů podle toho jak často se používají:
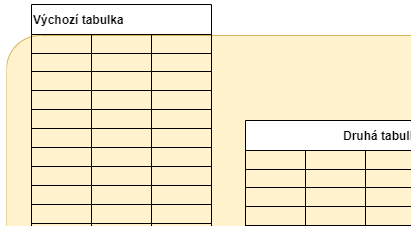
- LEFT JOIN (je to totéž jako LEFT OUTER JOIN, to slovíčko OUTER je nepovinné).
Výchozí tabulka všechny záznamy, sloupce z druhé tabulky pro nenalezené budou null
Používá se nejčastěji. - JOIN (je to totéž jako INNER JOIN, to inner se nepíše)
Ořízne to výchozí tabulku že obsahuje na řádky, kde existuje shoda na druhou tabulku.
Používá se jen pokud vím že ve výchozí tabulce existuje vždy odpovídající záznam v druhé.
Třeba k tabulce lcs.organizace dotahuji lcs.subjekty. Ale ne když k organizaci dotahuji zemi.
JOIN se dá napsat jako LEFT JOIN s podmínkou ve WHERE (b.Sloupec is null). - RIGHT JOIN – nepoužívat. Pokud někde vidím RIGHT JOIN, buď ten select psal začátečník který neví co dělá, nebo profesionál s výrazně větší znalostí SQL než mám já. Standardně vycházíte z jedné tabulky a dotahujete další a další pomocí LEFT JOIN. Tak se do dobře číst. Jak do toho vložíte RIGHT join, tak se ztratíte.
- FULL JOIN .
Používám se pokud porovnávám dvě tabulky a chci vidět záznamy z obou tabulek nevyhovující podmínce.
Někdy je lepší použít dva LEFT JOINY – nejprve SEELCT zleva a pak SELECT zprava (obrátit výchozí tabulku). - SELF JOIN – to v podstatě není join, ale stará syntaxe, když se ještě nepoužívaly joiny. Pozná se tak že za FROM je více tabulek oddělených čárkami a spojovací podmínka je ve WHERE.
- LEFT JOIN (je to totéž jako LEFT OUTER JOIN, to slovíčko OUTER je nepovinné).
- Kontrolujte si počty!
Agregace
- Standardní SELECT vrací tabulku.
- Pokud chci vrátit pouze jeden agregovaný řádek použiji na agregovatelný sloupec agregovatelnou funkci:
- SUM, AVG, COUNT
- Pokud chci více řádků a u nich mít agregované hodnoty, musím použít GROUP BY. Chci třeba počet organizací podle měst.
SELECT
o.misto
,count(*) as Pocet
,max(misto) as Maximum
,max(misto) as Minimum
FROM lcs.organizace o
GROUP BY o.misto- select nemůže mít více WHERE, ale můžu chtít na výslednou agregovanou tabulku použít WHERE, takže se používá HAVING.
Takže HAVING je WHERE následující po GROUP BY - Hodně používanou funkcí je SELECT COUNT(*) FROM TABULKA. Standardně so dávám vždycky nad JOINY, abych si mohl průběžně kontrolovat počty.
UPDATE
- Druhý nejpoužívanější příkaz po select.
- SELECT může maximálně trvat dlouho (a tím všechny zaseknout) ale nic nezkazí.
- UPDATE mění hodnoty sloupce ve výsledku a když nemáte správně JOINY nebo WHERE nebo jste na špatné databázi – můžete updatem změnit hodnotu v celé tabulce.
- Nejdříve vždy píšu SELECT a pak ho měním na UPDATE a vždy si kontroluji počet záznamů
- Syntaxe nejprve si napíšu select kde si dám sloupce které chci měnit. Vždycky sloupec (aktuální hodnota) a Nová hodnota.
SELECT exchange_address, 'Není', o.Poznamka, 'Zmenil pankostka@gmail.com'
-- select count(*)
-- select TOP 100 o.*
from lcs.Organizace o
left join lcs.zeme z on z.cislo_subjektu = o.zeme
where z.iso_kod_zeme = 'PY'- A pak změním SELECT na UPDATE
Zakomentuji ten select
Na začátek dám řádek UPDATE AliasVychoziTabulky SET
A pak
SLOUPEC1 = HODNOTA1
,SLOUPEC2 = HODNOTA2
UPDATE o SET
o.exchange_address = 'Není'
,o.Poznamka = 'Zmenil pankostka@gmail.com'
-- SELECT exchange_address, 'Není', o.Poznamka, 'Zmenil pankostka@gmail.com'
-- select count(*)
-- select TOP 100 o.*
from lcs.Organizace o
left join lcs.zeme z on z.cislo_subjektu = o.zeme
where z.iso_kod_zeme = 'PY'- Pozor měnit se dá jen výchozí tabulka (ta co je za FROM). Pokud to tak nemáte, musíte přepsat.
- Bacha na Helios kde reference_subjektu a nazev_subjektu mohou být ve dvou tabulkách současně.
INSERT
- Insert je na vkládání hodnot
- Buď se ty hodnoty vyjmenují nebo se dělá INSERT SELECT
- Opět většinou vycházím ze SELECT, který měním na INSERT
Subselect
- Standardně mám SELECT SLOUPEC FROM TABULKA
- Ale to TABULKA nebo SLOUPEC můžu nahradit tzv. Subselectem. Je to prostě select v kulatých závorkách, který musí mít alias
- Například SELECT * FROM (SELECT * FROM lcs.organizace) subs
- Pro sloupec musí ten subselect vracet jeden sloupec a jeden řádek. Obvykle se tedy používá:
- SELECT (SELECT TOP 1 z.iso_kod_zeme FROM lcs.zeme z WHERE z.cislo_subjektu = o.zeme ) FROM lcs.organizace o
- V subselectu se můžu odkázat na vnější tabulky (doporučuji používat jednoznačné aliasy).
- Hodně se používají ve výrazech v šablonách Heliosu.
TMP tabulky
- Moje tajná lááska
- Jakmile máte hodně komplikovaný SELECT se spoustou joinů, bude se špatně číst, nebude moc rychlý a ladit ho bude peklo.
- TMP tabulky pomůžou. Uděláte si jednoduchý select a strčíte si výsledek do TMP tabulky. Nad ní si uděláte nějaký update, nebo ještě lépe si z TMP uděláte další TMP a tak pokračujete.
- TMP tabulky se poznají tak že začínají #.
- Používá se obvykle konstrukce SELECT INTO. Prostě nad FROM se dá řásdek
INTO #MOJETMP - Existují v rámci session (jen v tom okně), schválně si to zkuste.
DROP TABLE IF EXISTS #zeme
SELECT DISTINCT o.zeme
INTO #zeme
FROM lcs.Organizace o
SELECT * FROM #zemeNevlezlo se/Ostatní
- Transakce
- WITH (Nolock)
- Velikosti písmen
- Collation
- Kopírování názvů sloupců ze výsledku selectu
- Uložené procedury, Funkce, View, Triggery
Zajímavé linky:
PS. Gutenberg for WordPress is SHIT, SHIT SHIT!
Napsat komentář
Pro přidávání komentářů se musíte nejdříve přihlásit.