Chci se sepsat jak formátovat SQL kód, aby byl pro mě čitelnější a lépe se upravoval.
Vycházím především ze své praxe, co se mi osvědčilo.
Snažím se aby byl kód především dobře čitelný, a dále chci co nejméně psát.
Příkladová data
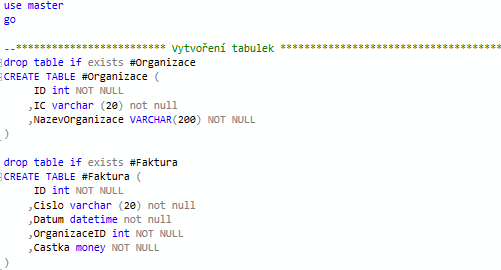
Vytvořím si na začátek dvě dočasné tabulky, na kterých budu ukazovat. A vložím do nich data.
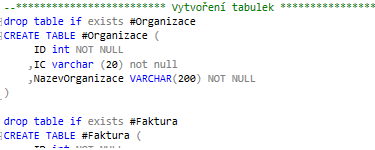
DROP TABLE IF EXISTS #Organizace --tabulka s organizacemi, (odběrateli)
CREATE TABLE #Organizace (
ID int NOT NULL
,IC varchar (20) not null
,NazevOrganizace VARCHAR(200) NOT NULL
)
DROP TABLE IF EXISTS #Faktura --tabulka s fakturami (vydanými) na organizaci.
CREATE TABLE #Faktura (
ID int NOT NULL
,Cislo varchar (20) not null
,Datum datetime not null
,OrganizaceID int NOT NULL
,VystavilID int NULL
,Castka money NOT NULL
)
DROP TABLE IF EXISTS #Zamestnanci --tabulka se zaměstnanci.
CREATE TABLE #Zamestnanci (
ID int NOT NULL
,PrijmeniJmeno varchar (20) not null
)
INSERT INTO #Organizace (ID,IC,NazevOrganizace)
VALUES
(1,'11111','PanKostka s.r.o.')
,(2,'22222','Nabla a.s.')
,(3,'33333','Fake a.s.')
INSERT INTO #Faktura (ID,Cislo,Datum,OrganizaceID,VystavilID,Castka)
VALUES
(1,'2020/01','2020-03-01',1,1,1000)
,(2,'2020/02','2020-03-01',2,1,500)
,(3,'2020/03','2020-03-01',1,2,2500)
,(4,'2020/04','2020-03-01',3,2,7333)
INSERT INTO #Zamestnanci (ID,PrijmeniJmeno)
VALUES
(1,'Dvořák Jiří')
,(2,'Dvořáková Zuzana')A1 Čárky na začátek
Čárky pro oddělování sloupců nedávat na konec, ale na začátek. Tím že je napíšu na začátek, na první pohled vidím, kde chybí. V níže uvedeném SQL je jedna čárka vynechána. Schválně kde to najdu rychleji?
Než jsem začal psát čárky na začátek, moje nejčastější chyba byla Incorrect syntax near ‚,‘. Nedělal jsem nic jiného, než hledal čárky.
-------------- Čárky na začátku - OK -------------------
SELECT
f.Cislo
,f.Datum
o.NazevOrganizace
,f.Castka
FROM #Faktura f
LEFT OUTER JOIN #Organizace o on o.ID = f.OrganizaceID
-------------- Čárky na konci - KO -------------------
SELECT
f.Cislo,
f.Datum,
o.NazevOrganizace
f.Castka
FROM #Faktura f
LEFT OUTER JOIN #Organizace o on o.ID = f.OrganizaceIDMůj oblíbený online formátovač poorsql.com to dělá stejně.
A2 Nelogická podmínka WHERE 1=1
Většinou mám v selectu více podmínek za WHERE. A často potřebuji některou z podmínek zakomentovat. Pokud první podmínku napíšu hned za WHERE, nejde jednoduše zakomentovat. Proto si pomáhám formulací WHERE 1=1 a podmínky jsou pak každá na samostatném řádku a začíná AND.
SELECT
f.Cislo
,f.Datum
,f.Castka
FROM #Faktura f
WHERE 1=1
--AND Castka <> 0 --TOTO JE ZAKOMENTOVÁNO
AND Datum > '2020-01-01'Výhodou je nejen snažší komentování, ale i přehlednost. Taky většinou to WHERE nezapomenu (Pokud jsou poslední podmínky na spojení tabulek a já přidám podmínku AND (bez WHERE), select projde, ale vrací něco úplně jiného )
A3 OR vždy v závorce
Standardní podmínky za WHERE (nebo při spojování tabulek) jsou nejčastěji AND Něco. Omezují počet řádků, které mi SELECT vrací. Ale někdy je potřeba dát i OR. Typicky to bývá když je někde výčet hodnot.
Třeba chci všechny faktury nad 1000 na organizaci A NEBO (=OR) organizaci B.
Bez výjimky, jakmile se vyskytne OR, dávám OR do závorek. A snažím se ho oddělit, abych nenarušil podmínky AND.
SELECT
f.Cislo
,f.Datum
,f.Castka
FROM #Faktura f
WHERE 1=1
AND Castka <> 0
AND (f.organizaceID = 1 OR f.OrganizaceID = 2) --OR musí být vždy v závorce.
AND Datum > '2020-01-01'A4 Psaní JOIN
Nově budu psát LEFT JOIN. Dříve jsem psal LEFT OUTER JOIN, ale je to stejné a je to zbytečné slovo navíc.
Používám tak ze 70%. Nejčastější spojovací podmínka. Mám tabulku a k ní dotahuji další.
Nikdy nepoužívám RIGHT JOIN. Nedává to smysl.
Píšu JOIN nikoli INNER JOIN. To slovo je zbytečné.
Používám tak z 20%. Obvykle když je vazba před ID které je povinné. A i tak si to promýšlím. Obvykle vycházím z jedné tabulky a přitahuji další. Když použiji LEFT JOIN, vím že SELECT vrátí z výchozí tabulky všechny záznamy a kde podmínka není splněna bude null. Pokud bych dal JOIN a podmínka nebude splněna, ořeže mi to i výchozí tabulku, což obvykle nechci.
Píšu FULL JOIN místo FULL OUTER JOIN.
Používám velmi zřídka, cca 5% případů. Typicky na reporty kde se porovnávají dva sety. Kde potřebuji vidět obě tabulky a kde se nesetkávají. Kdysi jsem používal porovnání zleva a zprava (přesněji zleva a zleva při obrácených tabulkách, nikdy RIGHT JOIN).
Píšu CROSS JOIN aby bylo jasné že se jedná o kartézský součin. Dříve jsem psal prostě JOIN bez spojovací podmínky a do komentáře jsem tučně psal — POZOR KARTÉZSKÝ SOUČIN!.
Používám velmi zřídka, cca 2% případů. Většinou v OLAP kostkách, třeba analýza nákupního košíku nebo rozgenerování záznamů do času apod.
Starou syntaxi, kdy se dává spojení tabulek do WHERE (místo JOIN) jsem použil tak před deseti lety.
A5 Podmínky za JOIN do jednoho řádku
Podmínky spojení za ON píšu do jednoho řádku (obvykle). Je to jinak než se obvykle doporučuje. Pro mě je ten kód výrazně přehlednější, protože když čtu co ten select dělá, nejprve procházím jaké tabulky se připojují a pak teprve zkoumám jak. Pokud je podmínka spojení nějak výjimečné nebo atypická, dávám na konec komentář. Pokud je těch podmínek hodně, první dám normálně a ty další no nové řádky ale pod tu první. Pořád chci vidět tabulky nejdříve.
SELECT f.Cislo
,f.Datum
,o.NazevOrganizace
,z.PrijmeniJmeno
,f.Castka
FROM #Faktura f
LEFT JOIN #Organizace o
ON o.ID = f.OrganizaceID
LEFT JOIN #Zamestnanci z
ON z.id = f.VystavilID
--Toto se líbí mě
SELECT
f.Cislo
,f.Datum
,o.NazevOrganizace
,z.PrijmeniJmeno
,f.Castka
FROM #Faktura f
LEFT OUTER JOIN #Organizace o on o.ID = f.OrganizaceID
LEFT OUTER JOIN #Zamestnanci z on z.id = f.VystavilIDV mém oblíbeném poorsql je to volba “ Break Join ON Sections“ která je implicitně nazaškrtnutá = jako to používám já.
A6 Keywords klidně malými
Klíčová slova jako SELECT, WHERE, FROM, CASE, atd. by se měla psát velkými písmeny. Obvykle to moc neřeším, protože je mám všude barevně zvýrazněná a obvykle to stačí. Něco píšu opravdu vždy velkými (typicky CASE, WHERE, END) něco různě (select, from).
-- Keywords malými podle mě není takový problém
select
f.Cislo
,f.Datum
,o.NazevOrganizace
,f.Castka
from #Faktura f
left join #Organizace o on o.ID = f.OrganizaceID
where 1=1
-- Keywords velkými
SELECT
f.Cislo
,f.Datum
,o.NazevOrganizace
,f.Castka
FROM #Faktura f
LEFT JOIN #Organizace o ON o.ID = f.OrganizaceID
WHERE 1=1A7 Pomocné select top 100 *
V selectu (ale i updatu) si velmi často si nechávám na konci sloupců pomocné řádky.
— SELECT TOP 100 *
— SEELCT TOP 100 f.*
— SELECT count(*)
SELECT
f.Cislo
,f.Datum
,o.NazevOrganizace
,f.Castka
-- SELECT TOP 100 *
-- SELECT TOP 100 f.*
-- SELECT COUNT(*)
FROM #Faktura f
LEFT JOIN #Organizace o ON o.ID = f.OrganizaceID
WHERE 1=1Když se pak chci podívat na počet záznamů, vyznačím si jen odpovídající část. Zrychluje to ladění, z výsledku selectu si můžu nakopírovat názvy sloupců (pravé tlačítko na záhlaví výsledku/Copy with headers) apod.
A8 V proceduře dávám parametry
Uložená procedura s parametry se hůř ladí, protože ty parametry/proměnné jsou deklarované na začátku. Obvykle ty parametry/proměnné vydeklaruji znovu zakomentované takto:
/*
Declare @parametr Char(1) = ‚A‘
— */
Finta je v tom zakomentování komentáře pomocí –. Prioritu má totiž */ ale jen pokud se najde začátek. Takže když vyznačím kód od toho Declare, krásně to projde.
-- Toto nemá vliv na běh procedury
/*
Declare @parametr1 char(1) = 'A'
-- */
-- a pokud vyznačím jen níže uvedenou část, je to opět korektní.
Declare @parametr1 char(1) = 'A'
-- */A9 Update vždy nejprve jako select
Nikdy nepíšu rovnou UPDATE/DELETE. Vždycky píšu nejprve SELECT, podívám se na výsledek a počet záznamů a pak ten select změním na UPDATE/DELETE.
UPDATE f SET
f.Castka = 5000
-- SELECT f.Cislo,f.Datum,o.NazevOrganizace,f.Castka
FROM #Faktura f
LEFT OUTER JOIN #Organizace o on o.ID = f.OrganizaceID
WHERE 1=1
AND f.Cislo = '2020/01'
DELETE f
-- SELECT f.Cislo,f.Datum,o.NazevOrganizace,f.Castka
FROM #Faktura f
LEFT OUTER JOIN #Organizace o on o.ID = f.OrganizaceID
WHERE 1=1
AND f.VystavilID = 2
A10 Vyhýbám se mezerám za čárkou
Normálně prostě sloupce oddělené čárkou, mezera je tam zbytečná. Čsto mám v selectu desítky sloupců, čím kratší tím lepší. Posunování pomocí CTRL + šipka funguje správně, vyznačení doubleclickem taky.
-- Sloupce prostě oddělené čárkami
INSERT INTO #Organizace (ID,IC,NazevOrganizace)
--Toto je zbytečně dlouhé
INSERT INTO #Organizace (ID, IC, NazevOrganizace)A11 Komentuji
Opravdu hodně komentuji. Až extrémně hodně. V proceduře před každým updateme, selectem píšu co vlastně chci. Když potom čtu tu uloženou proceduru, čtu nejprve co ten kód má dělat (komentář) a pak teprve co skutečně dělá. Dost často se stává, že už tímto objevím chybu.
Používám komentáře jak v řádku –, tak uvnitř /**/
Pro oddělení kusů kódů používám
–***************************** Text **********************************
———————- Text
–Text
Závěr
Nějak jsem se rozepsal víc než jsem myslel. A ještě mi toho dost zbylo. Snad se k tomu někdy dostanu.
Rád bych si sepsal jmenné konvence (naming conventions) jaké mi vyhovují (CamelToe CamelCase rules!, primární klíč jen ID! atd.)
Název sloupce (tabulky) s diakritikou musí být v hranatých závorkách []. Používá se velmi zřídka (třeba když odesílám TMP tabulku mailem).
Linky
Pro další tipy se snažím googlit na klíčová slova „sql syntax best practices“, „Formátování SQL“.
* sqlstyle.guide – Většina těch zásad mi připadá přesně obráceně než používám. Nelíbí se mi to moc.
* dzone.com/24-rules-to-the-sql-formatting-standard
Napsat komentář
Pro přidávání komentářů se musíte nejdříve přihlásit.